
Графоаналітичний метод
Принципи відбору лексичного матеріалу для досліджень розглядаються окремо
Застосовуваний в дослідженнях метод, названий автором графоаналітичним, є одночасно способом і засобом пізнання взаємин близько споріднених мов на ранній стадії їхнього розвитку, обумовлених особливостями природного середовища. Він був вперше описаний в 1987 р. в статті "Определение мест поселения древних славян графоаналитическим методом" в часописі "Известия Акадамии наук СССР. Серия литературы и языка". Фактично цей метод є практичною реалізацією теоретичного міркування українського філолога Іларіона Свєнціцького, який, відстоюючи необхідність застосування математики в гуманітарних науках, писав:
Важне тільки те, що всякі взаємини людські і взагалі світові найлекше означити числом, обємом і положенням у просторі і часі, через що вони легко укладаються в рямки математичних символів (Свєнціцкий І., 1927, 53)
Графо-аналітичний метод (GAM), дійсно, визначає відносне положення споріднених мов в просторі в певний час, що дозволяє досліджувати походження і розвиток мов в доісторичний період. Ідея методу полягає в геометричній інтерпретації взаємозв'язків споріднених мов на підставі кількісної оцінки спільних мовних одиниць в парах мов однієї мовної сім'ї або групи. Більша спорідненість мов звичайно пов'язується з великою кількістю загальних мовних одиниць, з яких для статистичної обробки найбільше підходять слова. Велика кількість слів дозволяє уникнути надмірної значущості окремих мовних одиниць для оцінки спорідненості, коли їх кількість мала. Відправною точкою при розробці методу було припущення про існування обернено пропорційній залежності між кількістю спільних слів (точніше лексем) в парі мов і відстанню між ареалами, на яких ці мови сформувалися. Простіше кажучи, чим ближче проживали один до одного носії двох споріднених мов, тим більше в їх мовах спільних слів. Ясно, що маються на увазі слова давні, такі, якими людина могла користуватися ще в доісторичні часи, а не ті слова, які виникли пізніше на більш високих щаблях суспільного розвитку. Виділити слова стародавнього походження непросто, але реально, для цього є є різні методи.
Метод дозволяє побудувати графічну модель родинних відносин мов однієї сім'ї або групи, для якої є тільки одне відповідність на поверхні Землі. Метод базується на використанні одного з виду графів, який, можливо, ще чекає свого опису в математиці (автор, принаймні, в теорії графів його не знайшов). Поки що його можна характеризувати як "виважений" граф, в якому зв’язки існують не між окремими вузлами, а обов’язково між ними усіма, при чому важливим є не тільки самий зв’язок, але і відстань між кожними з вузлів. Суть методу полягає в пошуку точних координат вузлів графа на підставі неточних даних про довжину ребер, котрі їх з’єднують. (У випадку, коли довжина ребер відома точно, відшукання цих координат не має великих труднощів, для геометрії це елементарна річ). В нашому випадку ми відшукуємо координати центрів місць поселень носіїв окремих мов, маючи неточні дані про кількість спільних слів в парах споріднених мов, тому і довжина ребер графу є приблизною. В принципі побудова графу є можливою, якщо довжина ребер не дуже спотворена, але вузли вже будуть виглядати не окремими точками, а множиною компактних точок. Чим компактніше будуть розташовані точки в межах множини і чим далі одна від одної розташовані ці множини, тим точніше побудований граф. Далі ми будемо будувати подібні графи в наших дослідженнях, але існує ймовірність того, що ці побудовані нами графи будуть виходити випадково. Спробуємо вирахувати цю ймовірність.
При існуванні графа A, який складається з деякого числа n вузлів, з’єднаних між собою ребрами, кожен вузол має (n – 1) ребер. Як відомо з математики, для розміщення точки на площині нам потрібно лише дві координати в будь-якій системі координат. Для нашого графа, комбінуючи відтинки ребер між собою по два, ми можемо отримати значно більше число пар координат. Точна їх кількість С, може бути обчислена за відомою формулою :
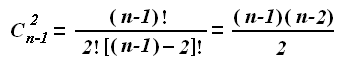
При числі вузлів n = 6 ми будемо мати кількість пар координат С = 10, при n = 10 кількість зростає до С = 36, при числі вузлів n = 12 ми отримаємо С = 55. Отже, при n більшому або рівному 6 місце кожного з вузлів графа відносно інших (n – 1) вузлів ми можемо отримати десятками різних способів. В нашому випадку для графа А при використанні всіх можливих способів розміщення вузлів на площині за допомогою ребер відомої довжини вузли завжди потраплять в одну точку. При дослідженні реальної системи, якою є наприклад система взаємин споріднених мов, нас задовольнить граф В, кожен з вузлів якого складатиметься з множини точок, котрі займають певну площу, що не перекривається площами інших вузлів. Якщо у нас, наприклад, число досліджуваних об’єктів n = 6 і вони займають площу, величина котрої S = 1, то кожен з об’єктів займе щонайбільше ділянку розміром s = 1/6. В такому випадку ймовірність того, що при побудові графа В хоча би одна точка потрапить на свою ділянку теж дорівнює 1/6. Для шести об’єктів кожен з його вузлів ми можемо побудувати десятьма різними способами, тоді ймовірність того, що всі десять разів одна і та сама вершина потрапить в ту саму площу буде дорівнювати одній шостій у десятим ступеню, тобто 1/604 660 176. Оскільки у нас шість об’єктів, то цю величину треба помножити саму на себе ще шість разів. Тоді у знаменнику буде величина з вісімдесятьма нулями. Вже ця величина не піддається уяві. Коли ж у нас число об’єктів буде збільшене до десяти, то кількість нулів у знаменнику буде дорівнювати 3600.
Щоб не ускладнювати сприйняття, наведений тут доказ був проведений дещо спрощено, але самі порядки отриманих величин говорять за те, що в разі побудови графу за наявними даними про її випадковість не може бути й мови. Зазначене спрощення пояснюється тим, що побудова точок за їх координатами дещо різниться від звичайної. Дійсно, в геометрії для побудови будь-якої точки потрібно мати тільки дві координати, але координати можуть мати додатні і від’ємні значення. Ми використовуємо тільки додатні числа, тому двома координатами можна побудувати дві точки, взаємні положення яких будуть дзеркальними. Метод побудови має певні особливості, коли логіка підказує, яку точку з двох можливих треба брати. Загальний хід побудови такий, що точки треба розташовувати від центру схеми, приблизне місце котрого стає відоме вже при побудові перших трьох центральних точок, тобто для тих мов, котрі мають між собою найбільше спільних слів (ознак), – спочатку відкладається відтинок, який відповідає найбільшій кількості слів в парі мов, а далі на базі цих двох точок по координатах будується третя. Власне тільки тут ми постаємо перед вибором – в який бік треба відкладати координати третьої точки, і це робиться довільно, тому кінцева схема може мати два варіанти, які дзеркально відбивають один одного. Але сумнівів при виборі одного з двох варіантів не буває ніколи, бо майже завжди відомо, які мови є західні, а які східні, чи північні або південні. Коли побудовано по одній точці кожного вузла, то тоді зникають всякі сумніви взагалі – з двох можливих варіантів береться той, при котрому точки одного вузла ляжуть найближче. Так робиться для всіх пар координат, але весь процес вимагає проведення кількох ітерацій, бо вибір початку координат (центру вузла) дещо довільний. Оскільки кожне ребро в якості координати використовується кілька разів в комбінації з іншими, то креслення стає перевантажене великою кількістю ліній і точок, серед яких можна заплутатися. Тому, коли дані досить точні, можна кожне ребро використовувати в якості координати тільки один раз. Тоді кожен вузол буде складатися тільки з (n – 1) точок, кожна з котрих є кінцем одного з ребер. Загальне число ребер дорівнює величині, котру можна вирахувати за формулою :
Графоаналітичний метод може знайти застосування не тільки в мовознавстві, але і в інших науках, де є наявною кореляція великої кількості спільних ознак різних об’єктів з відстанню, на якій розташовані ці об’єкти у просторі (необов’язково навіть у двомірному). Цей метод був перевірений, наприклад, на статистичних даних Федорова-Давидова (Федоров-Давыдов Г.А., 1987) про кількість спільних ознак орнаментальних композицій середньоазіатської кераміки, виробленої кількома різними майстрами, які мешкали в різних частинах Пенджикенту. Оскільки художні взаємовпливи майстрів були тим сильнішими, чим ближче вони один до одного мешкали, то виявилося можливим визначити розташування їх майстерень на території міста. Звичайно, перевірити ці дані неможливо, бо невідомо, де в дійсності мешкали майстри, але сама можливість побудови вже є певним свідченням дієвості методу.
Треба підкреслити особливо, що графоаналітичний метод ефективний при опрацюванні тільки абсолютних величин або віднесених до одної спільної. Відношення кількості спільних ознак між двома об’єктами до їх загальної кількості в цих мовах або в одній з них не може вповні характеризувати ці два об’єкти, бо загальна кількість ознак будь-якого з об’єктів сама залежить від розташування об’єкту серед інших. Маргінальні об’єкти мають меншу загальну кількість ознак, характерних для цієї асоціації, і це вже характеризує їхнє периферійне положення. Коли ж ми візьмемо цю зменшену кількість у знаменнику, вона нам штучно збільшить співвідношення. Це не означає, що маргінальні об’єкти взагалі мають менше ознак. Вони їх можуть мати навіть і більше, але їх частина може вже бути спільною не з об’єктами досліджуваної асоціації, а сусідньої.
Процес побудови схем спорідненості графоаналітичним методом за лексико-статистичними даними показаний на конкретному прикладі ностратичних мов з використанням результатів досліджень В.М.Ілліча-Світича (Иллич-Свитыч В.М., 1971). Ним були досліджені лексичні, словотворчі і морфологічні подібності шести великих мовних сімей Старого Світу : алтайської, уральської, дравідійської, індоєвропейської, картвельської і семіто-хамітської. Частина отриманих в результаті досліджень даних була подана в таблицях (морфологічні ознаки і лексика в кількості 147 позицій), а 286 лексичних паралелей можна було знайти в тексті, до яких при перевірці всього матеріалу з даними Андреєва ще було долучено 27 слів з уральських і 8 слів з алтайських мов (Андреев Н.Д., 1986). Тут необхідно зауважити, у складі всього матеріалу алтайських мов настільки переважають приклади з мов тюркських, що фактично саме про них і повинна була б іти мова, проте ми поки залишаємо термін «алтайські мови» в розумінні Ілліча Світича.
Після обробки усіх матеріалів Ілліча-Свитича і Андреева виявилося, що з 433 всієї кількості ознак 34 є спільними (до них ми ще вернемося), а решту склали 255 одиниць з уральських мов, також 255 – з алтайських, 253 одиниці з індоєвропейських, 240 – з семіто-хамітських, 189 – з дравідійських і 139 – з картвельських. Після цього була підрахована кількість спільних ознак в парах мов, але при цьому не враховувалася різна вагомість морфологічних ознак та лексичних одиниць, бо це зовсім різні категорії. Однак кількісна оцінка цієї вагомості все одно була б суб’єктивною, тому будемо надіятися, що морфологічні ознаки розподілилися серед мов більш-менш рівномірно. Підрахунки дали результати, подані в таблиці 1:
Таблиця 1. Кількість спільних ознак між сім’ями мов
| алтайські – уральські | 167 | уральські – картвельські | 66 |
| алтайські – індоєвропейські | 153 | індоєвропейські – семіто-хамітські | 147 |
| алтайські – семіто-хамітські | 149 | індоєвропейські – дравідійські | 108 |
| алтайські – дравідійські | 109 | індоєвропейські – картвельські | 70 |
| алтайські – картвельські | 84 | семіто-хамітські – дравідійські | 110 |
| уральські – індоєвропейські | 151 | семіто-хамітські – картвельські | 86 |
| уральські – семіто-хамітські | 136 | дравідійські – картвельські | 54 |
| уральські – дравідійські | 134 |
Проаналізувавши отримані дані, не можна одразу сказати про якусь певну їх закономірність, однак можна помітити, що найбільше спільних слів мають між собою алтайські, уральські, семіто-хамітські та індоєвропейські мови. З цих мов і слід починати побудову схеми. Спочатку треба вибрати коефіцієнт пропорційності, а далі перерахувати кількості спільних ознак у відстані між ареалами мов. Вибір значення коефіцієнту визначається розмірами аркушу, на котрому будується схема. Відповідно до наших даних підходить значення K = 1000. Тоді відстані між ареалами окремих мов будуть мати значення, подані в таблиці 2 :
Таблиця 2. Відстані між центрами мовних сімей на схемі, см
| алтайські – уральські | 6.0 | уральські – картвельські | 15.2 |
| алтайські – індоєвропейські | 6.5 | індоєвропейські – семіто-хамітсьські | 6.8 |
| алтайські – семіто-хамітські | 6.7 | індоєвропейські – дравідійські | 9.3 |
| алтайські – дравідійські | 9.2 | індоєвропейські – картвельські | 14.3 |
| алтайські – картвельські | 11.9 | семіто-хамітські – дравідійські | 9.1 |
| уральські – індоєвропейські | 6.6 | семіто-хамітські – картвельські | 11.6 |
| уральські – семіто-хамітські | 7.4 | дравідійські – картвельські | 18.5 |
| уральські – дравідійські | 7.5 |
Побудова схеми спорідненості іде в кілька ітерацій. Спочатку за двома координатами для кожної мови знаходиться одна точка, котра визначає приблизне положення її ареалу, а в наступних ітераціях іде уточнення розташування всіх ареалів мов. В принципі можна почати з будь-якої мови, але одразу невідомо, в який бік піде побудова, і схема може вийти за межі аркушу. Тому найзручніше почати побудову з пари мов, яка має найбільшу кількість спільних ознак. В нашому випадку це алтайські та уральські мови. Отже спочатку довільно розташуємо десь в центрі аркушу відтинок AB довжиною 6 см, який відповідає кількості спільних ознак у цій парі (див. Мал. 5). Кінці цього відтинку визначають місце точок для алтайських та уральських мов. Далі на базі цього відтинку будуються точки для індоєвропейських та семіто-хамітських мов. Почнемо з семіто-хамітських, оскільки ці мови мови мають більше спільних ознак з картвельськими і дравідійськими, ніж індоєвропейські. Відповідно до кількості спільних ознак точка семіто-хамітських мов має знаходитися на відстані 6,7 см від точки алтайських мов і на відстані 7,4 см від точки уральських мов. Циркулем з відповідним розчином робимо дві засічки і на їх перетині знаходимо точку семіто-хамітських мов. Таких точок може бути дві – зліва і справа від бази. Вибір однієї з цих двох можливих точок визначає кінцевий вигляд схеми, котра може мати два варіанти, дзеркальні один відносно другого.
Виберемо точку, котра лежить ближче до центру. Тепер ми маємо три точки – A, B, C і переходимо до побудови точки D (індоєвропейські мови). Її положення визначимо так само на базі відтинку AB . Вона має бути на відстані 6,5 см від точки A і на відстані 6,6 см від точки B. Циркулем робимо дві відповідні засічки в бік, протилежний від точки C і отримуємо точку D. (Розташовувати її поблизу точки C не можна, бо в цьому випадку семіто-хамітські і індоєвропейські мови повинні були би мати значно більше спільних ознак, ніж вони мають насправді). Точку E для дравідійських мов будуємо на базі BC, оскільки саме семіто-хамітські і уральські мови мають найбільше спільних ознак з дравідійською. Отже ця точка розміщується на відстані 7,5 см від точки уральських мов і на відстані 9,1 см від точки семіто-хамітських мов в напрямку від центра схеми, інакше вона ляже поблизу точки алтайських мов, чому суперечить кількість спільних ознак між ними. Аналогічно будується точка F для картвельських мов, тільки в цьому разі на базі AC. Перша ітерація закінчена – отримана скелетна схема спорідненості ностратичних мов. Їх ареали мусять бути десь в районі отриманих точок A, B, C, D, E, F.
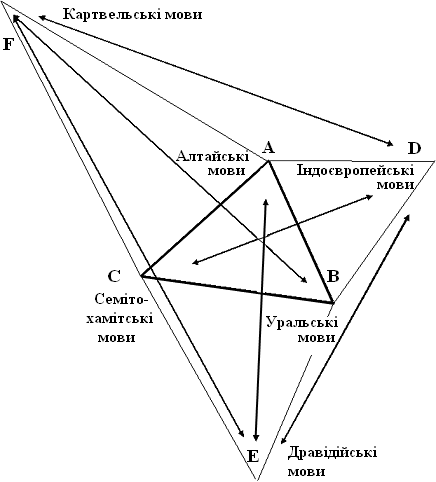
Мал. 5. Перша ітерація побудови схеми
спорідненості ностратичних мов.
Друга ітерація дає можливість уточнити і перевірити правильність розташування ареалів. При цьому точки окремих мов будують за іншими координатами. Наприклад, точка D будувалася за двома координатами, котрими були відтинки AD і BD. Тепер ми можемо використати в якості координат, скажімо, ті самі відтинки в інших сполученнях – з відтинками, котрі відповідають відстані ареалу індоєвропейських мов від ареалу дравідійських, семіто-хамітських та картвельських.
Потім можна взяти ще й інші сполучення. Разом ми мали би отримати 10 точок, котрі б нам окреслили ареал індоєвропейської мови. При цьому кожен раз при виборі одного з двох можливих варіантів ми мусимо вибирати той, при котрому нова точка лягає ближче до вже побудованих. На жаль, у випадку з ностратичними мовами не кожна пара координат дає нам можливість побудувати відповідну точку. Інколи координати є закороткими і не перетинаються між собою. Це пояснюється, очевидно, тим, що знайти спільні ознаки між мовами, котрі існували тисячі років тому надзвичайно важко, і таблиці Ілліча-Світича є недостатньо повними. Однак другу ітерацію можна провести простіше. З малюнку 5 вже добре видно, що центри ареалів індоєвропейської та семіто-хамітських мов мали би бути ближче один до одного, центр ареалу картвельських мов – ближче до алтайських, а центр ареалу дравідійських – ближче до семіто-хамітських і уральських. Пересунувши відповідно точки C, D, E, F, а потім з’єднавши між собою отримані таким чином нові центри ареалів прямими лініями, ми отримаємо граф, показаний на малюнку 6.
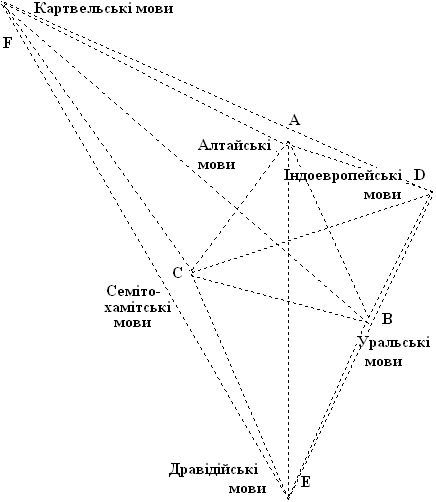
Мал. 6. Друга ітерація побудови схеми
спорідненості ностратичних мов
Після цього на кожну з ліній накладемо відповідні відтинки, розміри яких підраховані на основі кількості спільних слів в парах мов (див. вище), симетрично відносно середини відстані між вершинами графу. Тепер кінці відтинків будуть лежати більш компактно. Можна провести ще і третю ітерацію, якщо видно, що умовні центри ареалів треба пересунути знову. Остаточно схема родинних взаємин ностратичних мов приймає вигляд, поданий на малюнку 7. Отримана схема має певні фрактальні властивості, зокрема, нагадує трикутник Серпіньського.
Мал. 7. Схема взаємин ностратичних мов
Отримана таким чином схема є одним з двох дзеркальних варіантів, з котрих обрано саме цей з тої причини, що саме для нього вдалося знайти місце на географічній карті. Тут слід тільки зауважити, що при пошуках відповідного місця на географічній карті для отримуваних схем спорідненості треба кожен раз підбирати новий коефіцієнт пропорційності відповідно до масштабу карти, тобто будувати геометрично подібну схему іншого розміру відповідно до розмірів ареалів на карті. Ще раз зауважимо, що деформації схеми при цьому не робиться.
Побудова графічної моделі спорідненості за лексико-статистичними даними цілком може бути автоматизованим. Для цього треба скласти програму для комп'ютера. Це завдання для прикладної математики, в якій складання математичних моделей систем є звичайною справою. Автоматичні побудовані моделі викликали б більшу довіру, але взятися за таку роботу поки ніхто зі знайомих мені прикладних математиків не наважився. Очевидно, це все-таки не просте завдання.
Застосування графоаналітичного методу привело в кінцевому підсумку до відкриття феномену етноформуючих ареалів. Їх існування є свого роду емпірічним узагальненням, яке, за висловом Вернадського, "не відрізняється від науково встановленого факту" (Вернадский В.И. 2004, § 15).
Кількісні дані про лексику досліджену за допомогою графоаналітичного методу протягом сорока років.
| Сім'ї і групи мов | Кількість мов | Кількість ізоглос | Загальна кількість слів |
| Сино-тибетська | 7 | 2.775 | 9.700 |
| Тунгусо-маньчжурська | 11 | 2.234 | 10.200 |
| Монгольська | 8 | 2.250 | 8.500 |
| Ностратична | 6 | 433 | 2.600 |
| Абхазо-адизька | 5 | 1.800 | 4.500 |
| Нахско-дагестанська | 27 | 1.900 | 24.000 |
| Індоєвропейська | 14 | 2.554 | 12.381 |
| Фінно-угорська | 12 | 1.913 | 9.584 |
| Тюркська | 13 | 2.558 | 19.670 |
| Германська | 6 | 2.630 | 11.065 |
| Іранська | 11 | 1.773 | 8.249 |
| Слов'янська | 10 | 3.200 | 12.000 |
| Разом | 130 | ≈ 26.000 | ≈ 135.000 |

![]()